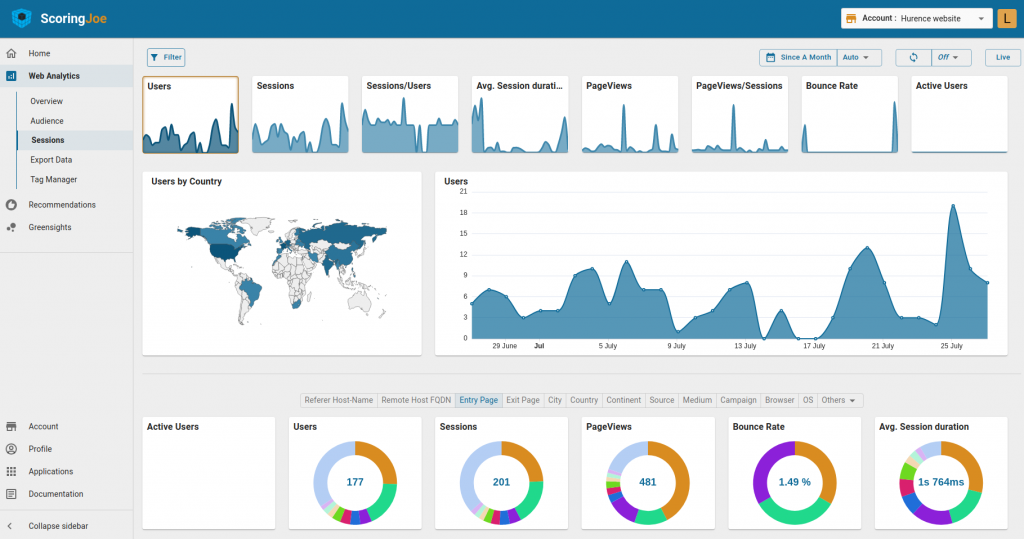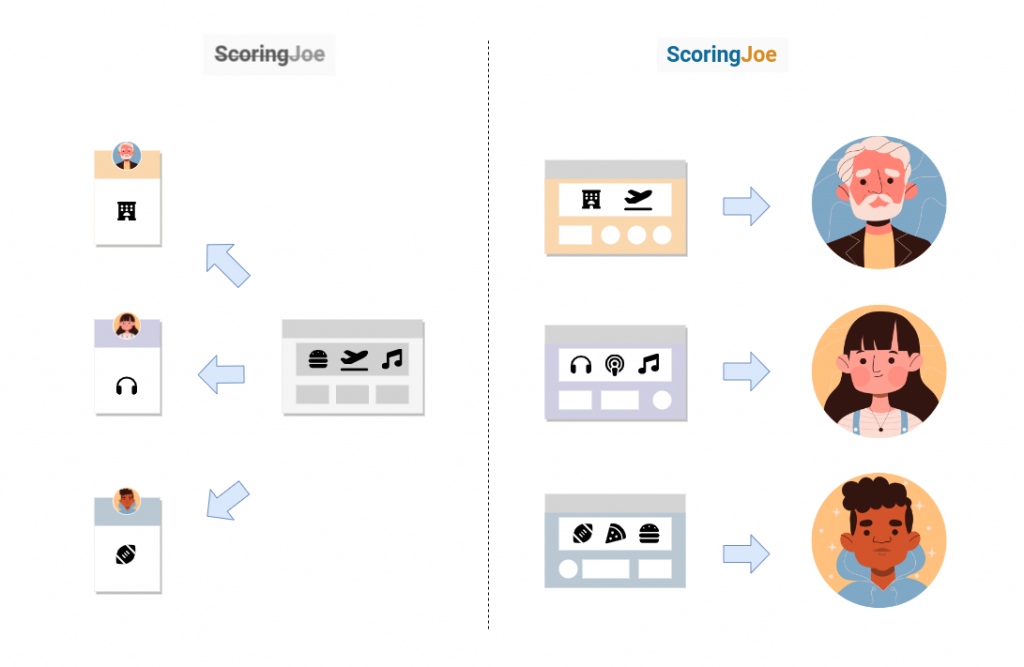
Article rédigé par Laurence Hubert, CEO hurence
Nous étions présents sur l’édition 2023 du salon du Big Data et de l’IA. Cette année nous nous sommes positionnés en observateurs (et non acteurs) car nous voulions prendre le temps de discuter avec nos collègues fournisseurs de solutions. Nous avons donc passé les deux jours du salon en discussions et démonstrations en profondeur avec un très bel accueil des acteurs que nous avons rencontrés, même quand nous nous étions identifiés comme concurrents. Nous avons beaucoup aimé les interactions techniques que nous avons eues ainsi que les échanges de très bonnes qualités dans les ateliers avec de grands noms venus présenter leurs visions (Google, IBM Consulting, Business Decision et Mick Levy etc.), dans le village startups et dans quelques coins reculés du salon, à l’abri du bruit du grand salon A des grands acteurs (grand merci au jeune démonstrateur de Illuin d’avoir assuré une démonstration malgré une sono proche). Nous ne pouvons pas tous les nommer mais merci à Airbyte (l’accueil de John et Chris), Actian (pour leurs délicieux jus de fruit et l’accueil de Vincent), Prisme.AI (et l’accueil de Bertrand), ThoughtSpot, Kairntech (et l’accueil de Vincent et l’équipe), Lettria, SnapLogic, ToucanToco (pour son pot sympa…), Data Galaxy etc, etc.
Cette année, le salon se séparait vraiment entre deux grands pôles: le pôle des fournisseurs de « plateformes data » recouvrant les fournisseurs de solutions pour les data mesh, lakehouse, et autres data warehouse. Et le pôle IA génératives. A noter, sur les deux pôles, la même tendance… plus personne ne code car les offres proposent du LOW CODE / NO CODE qui pour générer des flux d’ingestion ou de traitements de données – qui pour consommer de la donnée sous diverses formes. Ce que nous aimons dans la vie c’est que c’est un éternel recommencement. Nous avons passé presque une décennie à structurer les flux et la gestion de la Data mais vont maintenant pousser des myriades de petits flux ou analyses LOW CODE / NO CODE pour introduire une démocratisation mais aussi un peu de chaos dans notre univers Data. Chaos que nous passerons peut-être la prochaine décennie à structurer. D’ailleurs au vu de l’âge moyen sur les stands, les anciens de l’IT et du HPC/Big Data (Philippe de HPDIA ne me démentira pas), nous nous disons que c’est sans doute une aussi une nouvelle génération tech qui a éclos et que c’est aussi à un changement générationel, y compris au sein des équipes Hurence, auquel nous assistons.
Côté pôle « plateformes Data » quasi plus aucun acteur ne parle de data lake (ni même de data hub). Les concepts sont perçus comme « has been » à travers le discours marketing au profit de notions de Data Mesh. Mais… progressivement ce discours évolue. La mort du Data Lake a été annoncée de manière prématurée et cela a jeté nombre de décideurs dans un doute. Hors, il y a des réalités techniques dans les traitements sur grosses volumétries que nul ne peut ignorer car nos cas d’usage nous y confrontent assez rapidement et assez violemment. Les consultants accompagnant sur les approches Data Mesh ont dû, de fait, ajuster leurs présentations. De solution ou architecture miracle, le data mesh devient plus une approche de data gouvernance fédérée sur des sources de données décentralisées qu’une solution technologique de gestion de ces mêmes sources de données décentralisées… En effet, la réalité est tenace et nous avons toujours besoin de « consommer » de la donnée en volumétrie pour calculer nos modèles (IA ou non) à base de croisements de sources métier. Nous avons donc toujours besoin de les déverser quelque part et de faire les transformations d’un univers métier à un autre… Ce besoin donc de ce qu’on appelle un data lake (quelque soit le nom qu’on choisira de lui donner) nous ré-apprend que l’on ne traite pas des téraoctets de données juste en allant taper sur des APIs de data métier, en général incapables, souvent du fait des back-ends derrière, de tenir la charge des bombardements que font nos traitements Big Data parallélisés… Mais l’idée de démocratisation de la donnée et l’idée d’avoir des APIs de consommation de data et un vrai contrat de fourniture de données « propres » ont bien entendu leur valeur. Juste quelques possibles alertes issues de nos expériences et confirmées par nos clients rencontrés sur le salon et ayant expérimenté le paradigm de leur côté:
- Il s’avère que beaucoup de métiers ne veulent pas prendre la responsabilité de la gestion de l’exposition de leurs data via des APIs que l’on espère leur faire gérer dans une approche Data Mesh. Parce que ce n’est tout simplement pas leur métier! La théorie Data Mesh préconise un découpage logique et propre des domaines de données ce qui est, en soi, une bonne idée et une représentation de connaissance nécessaire. Par contre, le « ownership » du découpage physique de l’exposition décentralisée, ne va pas, lui, de soi, ni du point de vue culture, ni du point de vue technique. La gestion des données exposées sera probablement faite par un « métier spécialisé » et selon des modalités qui sont spécifiques au contexte… comme avant. Même si en effet des outils et des APIs de démocratisation de consommation doivent sans doute être fournis là où les données sont exposées.
- Personne n’ose encore remettre dans son architecture « slideware » la notion de Data Lake même si le discours évolue. Chez certains présentateurs un peu moins dans le flou artistique, le stockage S3 est mentionné à demi mot sur un socle bas niveau, comme si c’était purement anecdotique. En effet un des consommateurs de la donnée et un des fournisseurs « métier » de la donnée c’est notre Data Lake – S3. Car pour calculer un LLM – Large Language Model – pour obtenir un chatGPT spécialisé pour notre entreprise, il nous faut bien un endroit où l’on dépose toutes les sources « métiers » nécessaires à la vectorisation puis au calcul de ce merveilleux LLM. Et cet endroit « métier » sera également un fournisseur de données pour tous les métiers qui voudront utiliser ce LLM dans leur contexte. La réalité a donc la vie dure. Le Data Mesh n’est pas une architecture, c’est une approche vertueuse d’exposition des données de chaque métier par API – point. Et le Data Lake, peu importe comment on le nomme n’est ni has been ni inutile. Il correspond à un besoin de rassemblement d’une partie des données dans un socle commun pour assurer des performances de traitement sur des volumétries importantes et pour des métiers dits « de la donnée » – ceux qui créent de la donnée d’un plus haut niveau – qui donnent un sens « macro » à partir de la donnée « métier » plus élémentaire. C’est là que la donnée est transformée progressivement en connaissance et cela correspond à un métier à part entière, métier qui ne peut être délégué à une fédération d’entités !
Côté pôle IA Génératives, c’est une appétence jamais vue des entreprises et qui se retranscrit dans les offres de tous les acteurs. Aucun stand n’a oublié de mettre « IA génératives » dans sa communication et quelle que soit l’offre proposée. Nous disposons maintenant d’IA génératives pour créer des dashboard automatiquement, d’IA génératives pour générer du code de flux de données,… elles sont incontournables partout – et partout fleurissent des outils pour les créer. Elles sont aussi souvent les technologies sous-jascentes du LOW CODE, NO CODE. Tout le salon ressent que c’est un tournant dans l’IT, une vraie révolution telle qu’a pu l’être le moteur de recherche de Google il y a plusieurs décennies. Une vraie révolution dans l’interaction homme machine que toute application va devoir intégrer.